Récemment, certains ont évoqué une « faille » de
sécurité qui touche WebRTC : si vous utilisez un VPN, il est
possible d'obtenir votre adresse IP. Mais, comme nous allons le voir,
elle n'est pas nouvelle et faisait déjà parler d'elle il y a plus d'un
an. Ce problème avait même été anticipé dès les brouillons de WebRTC de
l'époque. Mais aucune protection n'a été mise en place depuis.
WebRTC
est un ensemble d'API permettant de gérer des conversations audio/vidéo
directement depuis un navigateur, sans plug-in à installer. Chrome et
Firefox le prennent nativement en charge, Mozilla l'exploitant par
exemple pour son client Hello disponible depuis
la mouture 34 de Firefox.
C'est l'histoire d'une « faille » WebRTC qui diffuse votre IP, même derrière un VPN
Problème, WebRTC présente une « faille » qui peut s'avérer
relativement gênante pour ceux qui utilisent un VPN et qui souhaitent
cacher leur adresse IP d'origine. Elle permet en effet à n'importe quel
site web de retrouver cette dernière, et non de s'arrêter
à celle du VPN, du moins sous Windows.
De très nombreux médias sont revenus sur cette affaire au cours des derniers jours, en évoquant notamment un prototype qui avait été mis en ligne
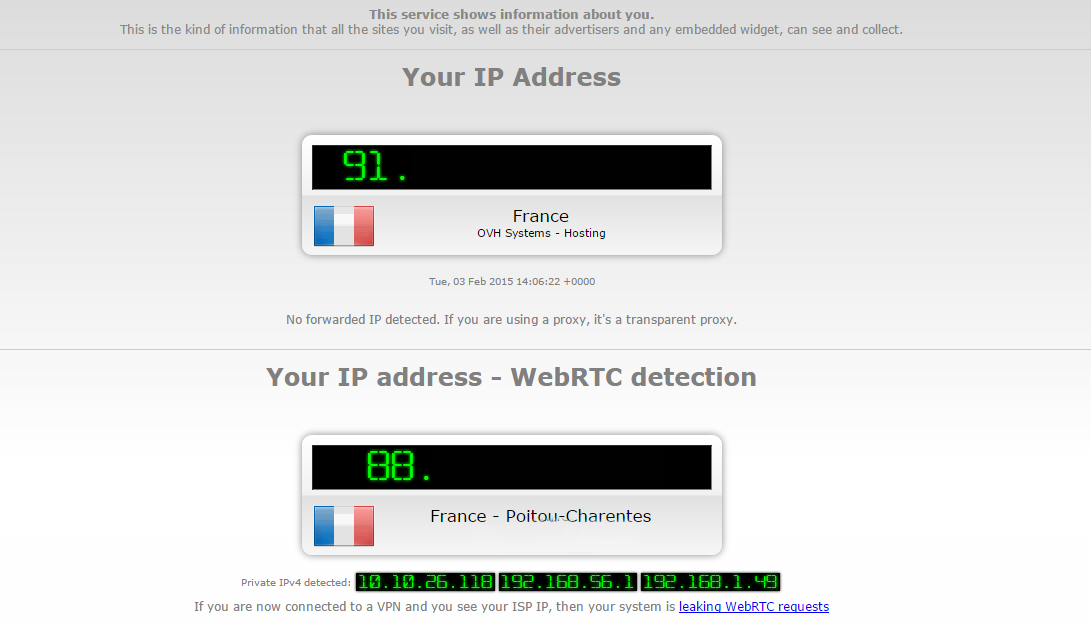
via ce dépôt Github. Pour tester cette « faille », il suffit de se rendre à
cette adresse via
un VPN pour constater que, dans la liste des adresses IP, celle de
votre connexion est bien présente aux côtés de celle du VPN.
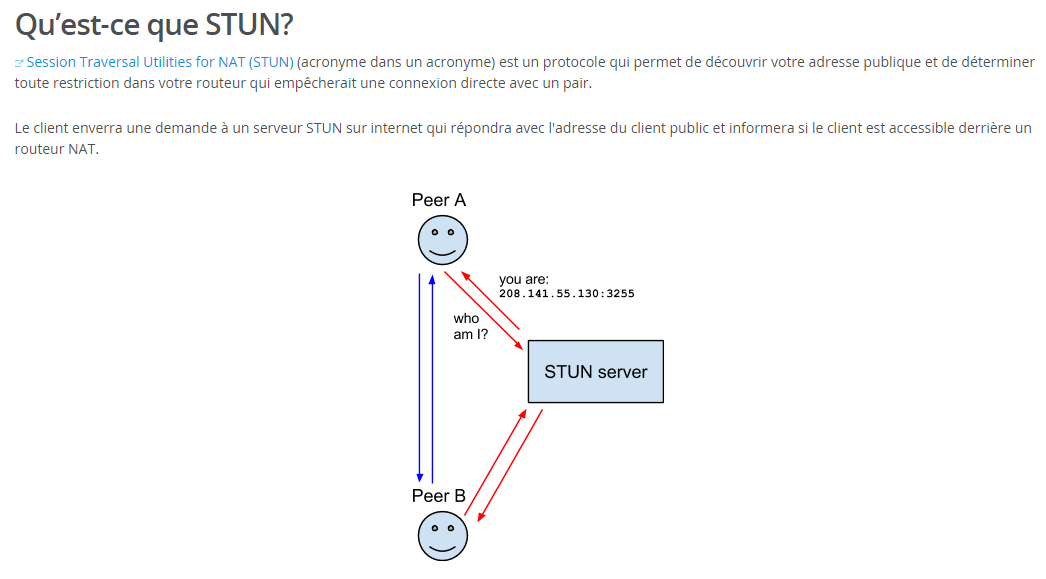
Cette situation est due au
protocole STUN (traversée
simple d'UDP à travers du NAT) développé par l'Internet Engineering
Task Force (IETF) qui permet à une application de connaitre l'adresse IP
réelle de la machine. Il est notamment utilisé dans les clients de type
VoIP ainsi que dans le protocole SIP. Il n'est donc pas anormal que
WebRTC récupère cette donnée, mais ce qui est plus inquiétant c'est que
cela se fasse sans que l'utilisateur en soit informé et sans qu'aucune
confirmation ne soit demandée. Mais de fait, cette situation n'a
absolument rien de nouveau.
Une « faille » dévoilée il y plus d'un an
En effet, après
quelques recherches, on découvre rapidement qu'il existe déjà une
extension Chrome permettant de bloquer cette « faille » :
WebRTC Block.
Détail surprenant, elle est en ligne depuis le 30 mai 2014 et, à
l'heure actuelle, toujours en version 1.0. Surprenant pour une « faille »
qui faisait parler d'elle fin janvier ? Pas tant que cela puisqu'elle
avait en fait
déjà été présentée fin mars 2014 par
@vitalyenbroder, là encore avec un prototype fonctionnel :
Suite aux papiers de différents médias de fin décembre/début janvier,
il a d'ailleurs mis à jour son blog, non sans une certaine dose
d'ironie : «
Le même problème de fuite VPN/IP a de nouveau été rendu
public par un programmeur américain et cela a soulevé beaucoup plus
d'intérêt sur Twitter et chez les magazines web. Conclusion : vous devez
être américain pour être entendu ? »
It's not a « faille », it's a « feature » !
Mais nous ne sommes pas encore au bout de nos surprises puisqu'on se
rend compte que, dès le mois de janvier 2014 (quelques mois plutôt
l'annonce de Vitalyenbroder), le cas d'un VPN utilisé avec WebRTC
était remonté via le
Bugzilla de Mozilla ainsi que sur
les forums de Chromium.
Du côté de la fondation au panda roux, l'importance du bulletin est
jugée comme « critique », mais uniquement depuis le 31 janvier 2015
(date à laquelle la vague d'articles est sortie dans la presse). Si l'on
regarde l'historique, on se rend compte qu'il était seulement considéré
comme « normal » auparavant. De son côté, Chromium a décidé de
classer ce problème avec les labels
entreprise et
vie privée, et non pas
sécurité.
Au-delà de ce classement, les réponses des développeurs sont tout
aussi intéressantes à étudier. Dans les deux cas, on retrouve en effet
une même remarque qui arrive rapidement sur le tapis et qui précise, en
substance, que
« ce comportement est dû à la conception même de WebRTC ». On retiendra principalement les interventions d'Eric Rescorla, auteur d'un des brouillons de WebRTC et fondateur de
RTFM,
sur Bugzilla, ainsi que de Justin Uberti, ingénieur logiciel, sur
le blog de Chromium. Au travers de leurs commentaires, ils renvoient
vers deux documents de l'IETF.
L'IETF avait anticipé ce problème dans les brouillons de WebRTC
Le paragraphe 5.4 du
premier document, qui est un brouillon de WebRTC, précise clairement les choses (nous sommes début 2014) : «
Un effet secondaire du fonctionnement du ICE [NDLR : Interactive Connectivity Establishment]
est que la machine distante connait l'adresse IP de la première, ce qui
donne de grandes quantités d'informations sur la géolocalisation. Cela a
des conséquences néfastes sur la vie privée dans certaines situations. »
Le second document est
un autre brouillon de WebRTC et, à la section 4.2.4 dédiée à la
localisation d'une adresse IP, on trouve le commentaire suivant : «
En
fonctionnement normal, les sites connaissent les adresses IP, mais elle
peut être cachée via des services comme Tor ou un VPN. Cependant, parce
que les sites peuvent obtenir l'adresse IP du navigateur, cela donne
aux sites un moyen de récupérer des renseignements sur le réseau de
l'utilisateur, même s'il est derrière un VPN afin de masquer son adresse
IP. » Il est ensuite précisé qu'il «
serait souhaitable que
les implémentations proposent des paramètres qui suppriment toutes les
adresses IP qui ne sont pas celles du VPN si l'utilisateur exploite
certains types de VPN, et en particulier des systèmes de protection de
la vie privée comme Tor ».
Des recommandations sont également formulées afin de proposer des
protections pour protéger l'adresse IP native dans le cas de
l'utilisation d'un VPN. L'API de WebRTC pourrait par exemple fournir une
solution afin de permettre à JavaScript de supprimer une demande de
connexion tant que l'utilisateur n'a pas décidé de répondre à l'appel.
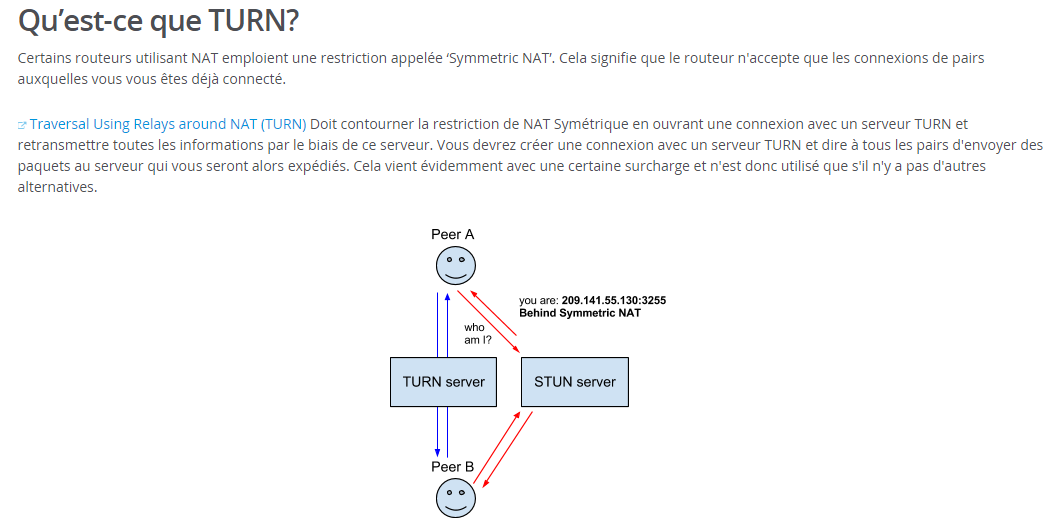
Il est également question de restreindre les connexions aux adresses
passant par un serveur TURN (
Traversal Using Relays around NAT),
ce qui aurait pour effet de protéger l'adresse IP native. Des
recommandations qui ne semblent pas avoir été spécialement suivies par
Mozilla et Google. Par contre, WebRTC est bien désactivé par défaut dans
dans Tor Browser (qui exploite Firefox).

 La différence entre STUN et TURN
La différence entre STUN et TURN
Au final, comment se protéger de cette « faille » liée à WebRTC avec Chrome et Firefox ?
Quoi qu'il en soit, il règne désormais une ambiance tendue avec une
certaine incompréhension entre les deux camps. D'un côté, ceux qui
pensent qu'il s'agit d'une « fonctionnalité » liée à WebRTC, qui
nécessiterait tout de même des ajustements afin de mieux protéger la vie
privée ou au moins donner plus d'information et de possibilités à
l'utilisateur. De l'autre, et ceux qui estiment qu'il est question d'une
importante faille de sécurité qui doit être corrigée.
Notez que pour vous protéger de ce genre de mésaventure, dans Firefox
il est possible de désactiver WebRTC par défaut. Pour cela, il faut
vous rendre dans « about:config » puis désactiver «
media.peerconnection.enabled ». Cette manipulation n'est pas possible
pour l'instant sur Chrome et il faudra donc passer par l'extension
WebRTC Block afin
de désactiver ce service. Le problème semblerait ne pas apparaitre
lorsque le VPN est configuré sur une box ou un routeur et pas
directement sur l'ordinateur sous Windows.
Avec l'ampleur médiatique des deux semaines précédentes, il sera
intéressant de voir comment vont régir les deux navigateurs par rapport
aux deux camps et aux différentes possibilités d'évolution. La situation
restera-t-elle la même, désactiveront-ils par défaut WebRTC ou bien
demanderont-ils une validation à l'utilisateur avant de transmettre
l'adresse IP ? La question reste pour le moment ouverte.
Notez néanmoins que cette dernière possibilité ne semble pas
spécialement plaire à Google qui indique, par la voix de l'un de ses
développeurs avoir «
considéré cette option, mais je ne pense
finalement pas qu'introduire une action de l'utilisateur soit logique.
Ce n'est pas une demande qui sera bien comprise ("voulez-vous que cette
application puisse dévoiler vos différentes interfaces réseau ? ")
». Après, rien n'empêche de modifier le message afin de mettre un
avertissement pour ceux qui utilisent un VPN, avec un lien vers des
explications détaillées si besoin.
On pourrait par exemple imaginer un système qui fonctionne comme les
demandes de géolocalisation qui peuvent être autorisées pour certains
sites mais pas pour d'autres (comme
lorsque les sites de presse veulent vous géolocaliser).